Introdução
Random forest é um algoritmo de aprendizado supervisionado, o qual é usado para a classificação de um bem como de regressão. Mas, no entanto, é usado principalmente para problemas de classificação. Como sabemos, uma floresta é feita de árvores e mais árvores significa uma floresta mais robusta., Da mesma forma, o algoritmo da floresta aleatória cria árvores de decisão em amostras de dados e, em seguida, obtém a previsão de cada um deles e, finalmente, seleciona a melhor solução por meio da votação. É um método ensemble que é melhor do que uma única árvore de decisão porque reduz o excesso de montagem, calculando a média do resultado.
Working of Random Forest Algorithm
we can understand the working of Random Forest algorithm with the help of following steps –
-
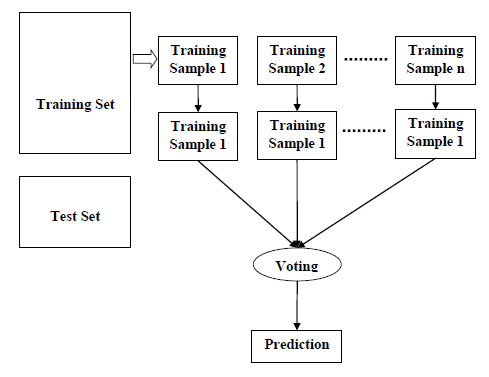
Step 1-First, start with the selection of random samples from a given dataset.,
-
Passo 2-a seguir, este algoritmo irá construir uma árvore de decisão para cada amostra. Então terá o resultado da predição de cada árvore de decisão.
-
Passo 3 – Nesta etapa, a votação será realizada para cada resultado previsto.
-
Passo 4 − por fim, selecione o resultado de previsão mais votado como o resultado de previsão final.,
O diagrama a seguir ilustra o seu funcionamento −
Implementação em Python
Primeiro, comece com a importação necessário pacotes Python −
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd
em seguida, baixar o iris dataset a partir de sua weblink como segue:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
em seguida, precisamos atribuir nomes de coluna para o conjunto de dados como segue:
headernames =
Agora, precisamos ler conjunto de dados para pandas dataframe como segue:
dataset = pd.read_csv(path, names = headernames)dataset.head()
de Dados pré-Processamento será feito com a ajuda de seguir linhas de script.,
X = dataset.iloc.valuesy = dataset.iloc.values
a seguir, vamos dividir os dados em comboio e ensaio dividido. O código a seguir irá dividir o conjunto de dados em 70% dos dados de treinamento e 30% de testes de dados
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30)
em seguida, treinar o modelo com a ajuda de RandomForestClassifier classe de sklearn como segue:
por último, precisamos fazer a previsão., Isso pode ser feito com a ajuda da seguinte script
y_pred = classifier.predict(X_test)
em seguida, imprimir os resultados da seguinte forma −
de Saída
Prós e Contras de Random Forest
Vantagens
A seguir estão as vantagens de Random Forest algoritmo
-
Ele supera o problema de overfitting pela média ou combinar os resultados de diferentes árvores de decisão.
-
florestas aleatórias funcionam bem para uma grande variedade de itens de dados do que uma única árvore de decisão.a floresta Aleatória tem menos variância do que a árvore de decisão.,
-
florestas aleatórias são muito flexíveis e possuem alta precisão.
-
a escala de dados não requer no algoritmo da floresta aleatória. Mantém boa precisão mesmo depois de fornecer dados sem escala.
-
algoritmos de floresta aleatória mantém boa precisão mesmo uma grande proporção dos dados está faltando.
Cons
as desvantagens do algoritmo da floresta aleatória −
-
a complexidade é a principal desvantagem dos algoritmos da floresta aleatória.,a construção de florestas aleatórias é muito mais difícil e demorada do que as árvores de decisão.
-
são necessários mais recursos computacionais para implementar o algoritmo da floresta aleatória.
-
é menos intuitivo no caso de termos uma grande coleção de árvores de decisão.
-
o processo de previsão usando florestas aleatórias é muito demorado em comparação com outros algoritmos.