médias de Carga em uma indústria-métrica crítica – a minha empresa gasta milhões de auto scaling instâncias de nuvem com base nelas, e outras métricas, mas no Linux há algum mistério em torno deles. Linux load averages track not just runnable tasks, but also tasks in the ininterruptible sleep state. Por quê? Nunca vi uma explicação. Neste post eu vou resolver este mistério, e resumir as médias de carga como uma referência para todos tentando interpretá-los.,
Linux load averages are “system load averages” that show the running thread (task) demand on the system as an average number of running plus waiting threads. Estas medidas exigem, o que pode ser superior ao que o sistema está actualmente a processar. A maioria das ferramentas mostra três médias, para 1, 5 e 15 minutos:
algumas interpretações:
- Se as médias são de 0, 0, então o seu sistema está ocioso.se a média de 1 minuto for superior à média de 5 ou 15 minutos, então a carga está aumentando.,se a média de 1 minuto for inferior à média de 5 ou 15 minutos, a carga está a diminuir.
- Se eles são mais elevados do que a sua contagem de CPU, então você pode ter um problema de desempenho (depende).
Como um conjunto de três, você pode dizer se a carga está aumentando ou diminuindo, o que é útil. Eles também podem ser úteis quando um único valor de demanda é desejado, como para uma regra de escala automática de nuvem. Mas compreendê-los mais detalhadamente é difícil sem a ajuda de outras métricas., Um único valor de 23-25, por si só, não significa nada, mas pode significar alguma coisa se a contagem de CPU for conhecida, e se for conhecida por ser uma carga de trabalho ligada à CPU.
em vez de tentar depurar as médias de carga, normalmente mudo para outras métricas. Vou discutir isto na secção” melhores métricas ” perto do fim.
Histórico
as médias de carga originais mostram apenas a demanda de CPU: o número de processos em execução mais aqueles que esperam para correr., Há uma boa descrição disso na RFC 546 intitulada “Tenex Load Averages”, agosto de 1973:
A média de carga TENEX é uma medida da demanda de CPU. A média de carga é uma média do número de processos executáveis ao longo de um determinado período de tempo. Por exemplo, uma média horária de carga de 10 significaria que (para um único sistema CPU) a qualquer momento durante essa hora se poderia esperar ver 1 processo em execução e 9 outros prontos para executar (ou seja, não bloqueados por I/O) esperando pela CPU.
a versão deste no ietf.,org links para um PDF scan de uma mão desenhada carga média gráfico a partir de julho de 1973, mostrando que esta tem sido monitorado por décadas:
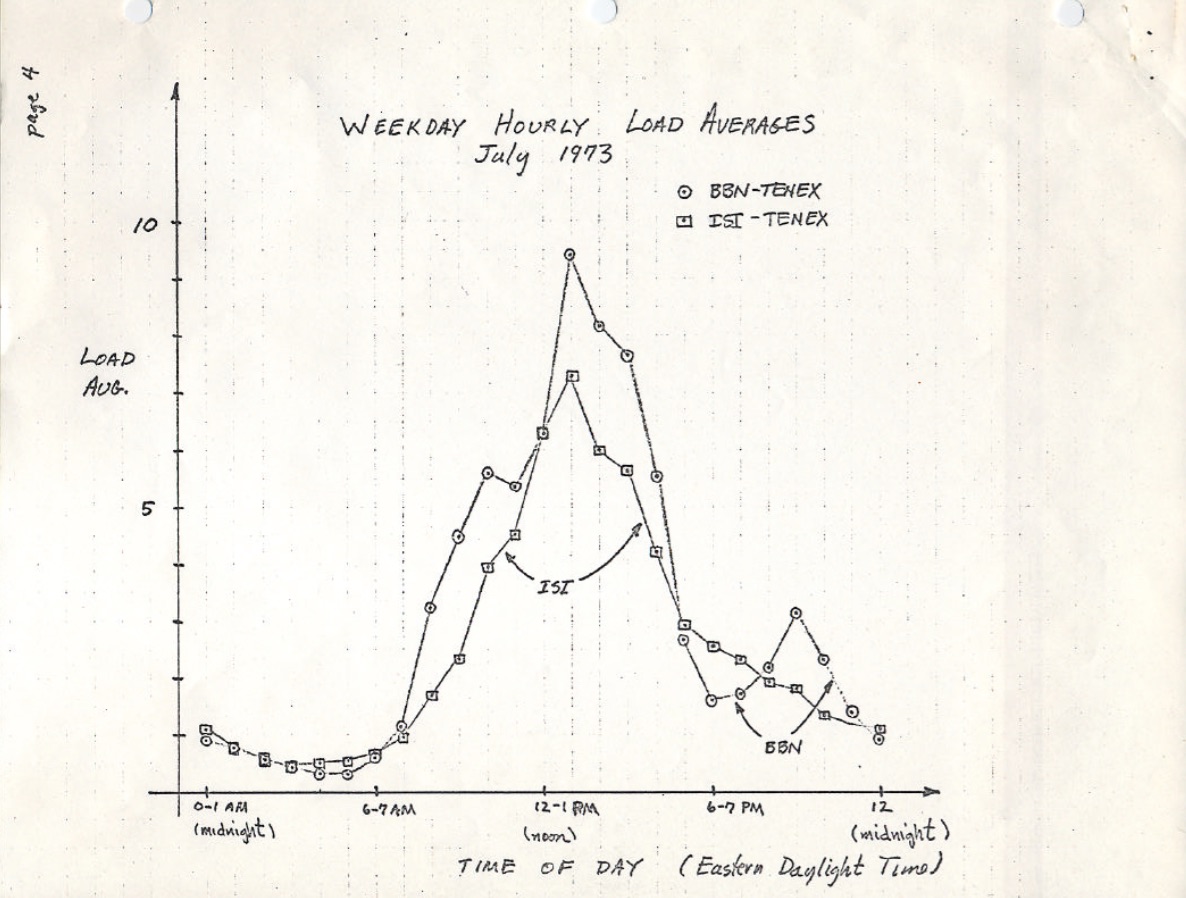
fonte: https://tools.ietf.org/html/rfc546
Hoje em dia, o código-fonte para sistemas operacionais mais antigos também podem ser encontrados on-line. Aqui está uma exceto da Dec macro assembly da TENEX (início dos anos 1970) SCHED.MAC:
E aqui está um trecho do Linux today (include / linux / sched / loadavg.h):
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */#define EXP_5 2014 /* 1/exp(5sec/5min) */#define EXP_15 2037 /* 1/exp(5sec/15min) */
Linux is also hard coding the 1, 5, and 15 minute constants.,
tem havido métricas médias de carga similares em sistemas mais antigos, incluindo Multics, que tinha uma média exponencial de agendamento na fila.
os três números
estes três números são as médias de carga de 1, 5 e 15 minutos. Só que não são médias e não são 1, 5 e 15 minutos. Como pode ser visto na fonte acima, 1, 5 e 15 minutos são constantes usadas em uma equação, que calcula somas móveis exponencialmente amortecidas de uma média de cinco segundos. As médias de carga de 1, 5 e 15 minutos resultantes refletem a carga muito além de 1, 5 e 15 minutos.,
Se você pegar um sistema de marcha lenta sem carga, em seguida, iniciar uma carga de trabalho simples de CPU (uma thread em um loop), qual seria a média de carga de um minuto após 60 segundos? Se fosse uma média simples, seria 1,0. Aqui é que a experiência, representados em gráficos:
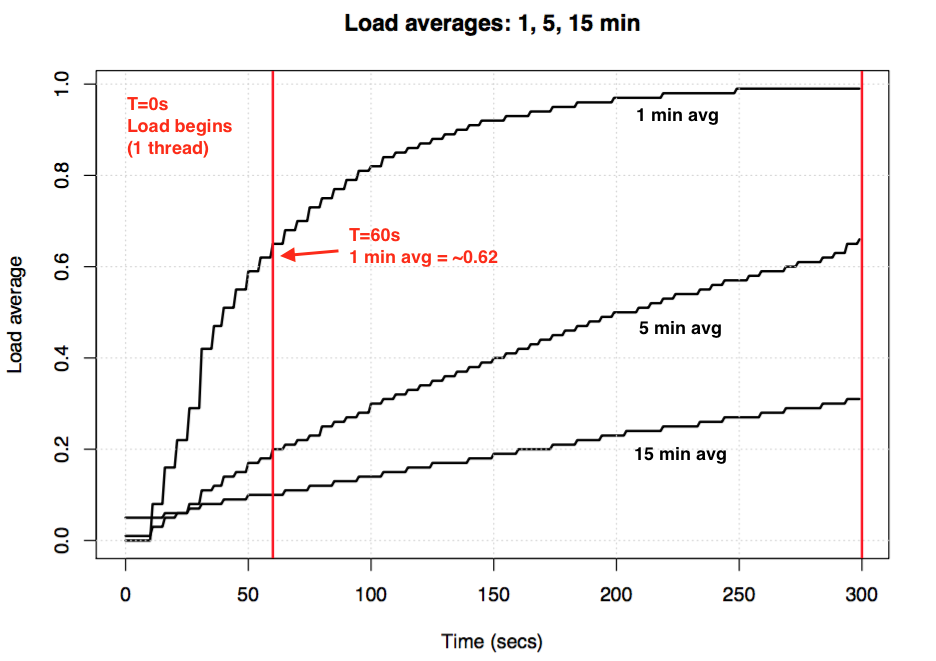
Carga média experimento para visualizar exponencial de amortecimento
Os chamados “um minuto média” só atinge aproximadamente 0,62 pela marca de um minuto. Para mais sobre a equação e experiências similares, Dr., Neil Gunther escreveu um artigo sobre médias de carga: como ele funciona, além de que existem muitos comentários em bloco de código Linux no loadavg.c.
Linux Tarefas ininterruptas
quando as médias de carga apareceram pela primeira vez em Linux, elas refletiram a demanda de CPU, como com outros sistemas operacionais. Mas mais tarde no Linux mudou-os para incluir não só tarefas executáveis, mas também tarefas no estado ininterrupto (TASK_ uninterruptible ou Nr_ uninterruptible). Este estado é usado por caminhos de código que querem evitar interrupções por sinais, que inclui tarefas bloqueadas no disco I/O e alguns bloqueios., Você pode ter visto este estado antes: ele aparece como o estado “D” na saída ps e top. O PS (1) man page chama-o de “sono ininterrupto (geralmente IO)”.
adicionar o estado ininterrupto significa que as médias de carga Linux podem aumentar devido a uma carga de trabalho de disco (ou NFS), não apenas a demanda de CPU. Para todos familiarizados com outros sistemas operacionais e suas médias de carga de CPU, incluindo este estado é no início profundamente confuso.porquê? Por que, exatamente, o Linux fez isso?
Existem inúmeros artigos sobre médias de carga, muitos dos quais apontam o Linux Nr_ uninterruptible gotcha., Mas não vi nada que explicasse ou arriscasse adivinhar porque é que está incluído. Minha própria suposição teria sido que ele é destinado a refletir a demanda em um sentido mais geral, em vez de apenas demanda CPU.
à procura de um patch antigo do Linux
compreender porque é que algo mudou no Linux é fácil: você lê o histórico de commit do git no ficheiro em questão e lê a descrição da alteração. Verifiquei o histórico do loadavg.c, mas a mudança que adicionou o estado ininterruptible antecede aquele arquivo, que foi criado com o código de um arquivo anterior., Eu verifiquei o outro arquivo, mas esse rasto também foi arquivado: o código em si tem saltado em torno de diferentes arquivos. Na esperança de tomar um atalho, eu despejei “git log-p” para todo o repositório Linux GitHub, que era de 4 Gbytes de texto, e comecei a lê-lo para trás para ver quando o código apareceu pela primeira vez. Isto também foi um beco sem saída. A mudança mais antiga em todo o repo Linux Data de 2005, quando o Linus importou o Linux 2.6.12-rc2, e esta mudança antecede isso.
existem acordos históricos Linux (aqui e aqui), mas esta descrição de mudança está faltando desses também., Tentando descobrir, pelo menos, quando esta mudança ocorreu, eu procurei tarballs em kernel.org e descobriu que tinha mudado em 0,99,15, e não em 0,99,13 – no entanto, a bola para 0,99,14 estava faltando. Eu encontrei em outro lugar, e confirmou que a mudança foi no Linux 0.99 patchlevel 14, Nov 1993. Eu estava esperando que o lançamento descrição para 0.99.14 por Linus explicaria a mudança, mas que também era um beco sem saída:
“Mudança para a última versão oficial (p13) são numerosos demais para mencionar (ou até mesmo para lembrar)…,”- Linus
he mentions major changes, but not the load average change.
de acordo com a data, eu olhei para o kernel mailing list archives para encontrar o patch, mas o mais antigo de e-mail está disponível a partir de junho de 1995, quando o sysadmin escreveu:
“Enquanto estiver trabalhando em um sistema para fazer essas endereçamento de arquivos escala moreeffecitvely eu acidentalmente destruído o atual conjunto de arquivos (ahwhoops).”
My search was starting to feel cursed., Felizmente, encontrei alguns arquivos antigos de listas de discussão linux-devel, resgatados de cópias de segurança do servidor, muitas vezes armazenados como tarballs de digests. Procurei mais de 6.000 digests contendo mais de 98.000 e-mails, 30.000 dos quais eram de 1993. Mas, de alguma forma, desapareceu de todos eles. Parecia realmente que a descrição original do patch poderia ser perdida para sempre, e o” porquê ” permaneceria um mistério.
a origem do ininterruptível
felizmente, eu finalmente encontrei a mudança, em um arquivo de caixa de correio comprimido a partir de 1993 em oldlinux.org., Aqui está:
é incrível ler os pensamentos por trás desta mudança de quase 24 anos atrás.
isto confirma que as médias de carga foram deliberadamente alteradas para refletir a demanda por outros recursos do sistema, não apenas CPUs. Linux mudou de” médias de carga de CPU “para o que se pode chamar de”médias de carga de Sistema”.
Seu exemplo de usar um disco swap mais lento faz sentido: ao degradar o desempenho do sistema, a demanda no sistema (medido como rodando + em fila) deve aumentar. No entanto, as médias de carga diminuíram porque eles apenas rastrearam os estados de execução da CPU e não os estados de troca., Matthias pensou que isto não era intuitivo, o que é, por isso arranjou-o.
Ininterruptible today
But don’t Linux load averages sometimes go too high, more than can be explained by disk I / O? Sim, embora o meu palpite seja que isso é devido a um novo caminho de código usando TASK_ uninterruptible que não existia em 1993. No Linux 0.99.14, havia 13 codepaths que definiam diretamente TASK_ uninterruptible ou TASK_SWAPPING (o estado de swapping foi mais tarde removido do Linux). Hoje em dia, no Linux 4.12, existem cerca de 400 codepaths que definem TASK_ INTRUPTÍVEL, incluindo alguns primitivos de bloqueio., É possível que uma destas cubas não seja incluída nas médias de carga. Da próxima vez que tiver médias de carga que pareçam muito altas, vou ver se é esse o caso, e se pode ser corrigido.
I emailed Matthias (for the first time) to ask what he thought about his load average change almost 24 years later. Ele respondeu em uma hora (como eu mencionei no Twitter), e escreveu:
“o ponto de “média de carga” é chegar a um número relacionado como o sistema é de um ponto de vista humano. TASK_ uninterruptible means (means?,) que o processo está esperando por algo como uma leitura de disco que contribui para a carga do sistema. Um sistema fortemente ligado ao disco pode ser extremamente lento, mas só tem uma média de execução de tarefas de 0,1, o que não ajuda ninguém.”
(obter uma resposta tão rapidamente, ou mesmo uma resposta em tudo, realmente fez meu dia. Obrigado!)
então Matthias ainda acha que faz sentido, pelo menos dado o que TASK_ INTRUPTIBLE costumava significar.
mas TASK_ UNITERRUPTIBLE combina mais coisas hoje em dia. Devemos mudar as médias de carga para ser apenas CPU e demanda de disco?, Programador de mantenedor Pedro Zijstra já me enviou uma inteligente opção para explorar para fazer isso: incluir task_struct->in_iowait em médias de carga, em vez de TASK_UNINTERRUPTIBLE, de modo a que mais se aproxima de disco I/O. Ele levanta outra questão, no entanto, que é o que realmente queremos? Queremos medir a procura no sistema em termos de fios, ou apenas a procura de recursos físicos? Se for o primeiro, então esperar por fechaduras ininterruptas deve ser incluído como essas threads são demanda no sistema. Não estão inactivos., Então talvez o Linux já funcione como queremos.
para entender melhor os caminhos de código ininterruptos, eu gostaria de uma maneira de medi-los em ação. Então podemos examinar diferentes exemplos, quantificar o tempo gasto neles, e ver se tudo faz sentido.
medindo tarefas ininterruptas
o seguinte é um grafo de chama Off-CPU de um servidor de produção, abrangendo 60 segundos e mostrando apenas pilhas de kernel, onde estou filtrando para incluir apenas aqueles no estado de TASK_ uninterruptible (SVG)., Ele fornece muitos exemplos de fontes de caminhos de código:

Se você é novo off-CPU chama gráficos: você pode clique nos quadros para ampliar, examinando o full stacks que aparecem como uma torre de quadros. O tamanho do eixo x é proporcional ao tempo gasto com o off-CPU bloqueado, e a ordem de ordenação (da esquerda para a direita) não tem significado real. A cor é azul para as pilhas off-CPU (eu uso cores quentes para as pilhas on-CPU), e a saturação tem variância aleatória para diferenciar as molduras.,
I gered this using my offcputime tool from bcc( this tool needs eBPF features from Linux 4.8+), and my flame graph software:
i’m using awk to change the output from microseconds to milliseconds. The offcputime “–state 2 ” matches on TASK_ uninterruptible (see sched.h), E é uma opção que acabei de Adicionar para este post. Josef Bacik do Facebook fez isso pela primeira vez com sua ferramenta kernelscope, que também usa gráficos bcc e flame. Em meus exemplos, estou apenas mostrando as pilhas de kernel, mas offcputime.py suporta mostrar as pilhas do Utilizador também.,
Como para o gráfico de chama acima: ele mostra que apenas 926 ms em 60 segundos foram gastos em sono ininterrupto. Isso só adiciona 0,015 às nossas médias de carga. É tempo de, em alguns cgroup caminhos, mas este servidor não está fazendo muita e/S de disco
Aqui é uma mais interessante, desta vez, apenas a inclusão de 10 segundos (SVG):

/* wait to be given the lock */ while (true) { set_task_state(tsk, TASK_UNINTERRUPTIBLE); if (!waiter.task) break; schedule(); }
Este é aquisição de bloqueio o código que está usando TASK_UNINTERRUPTIBLE., O Linux tem versões ininterruptas e interruptíveis do mutex adquirem funções (eg, mutex_lock () vs mutex_lock_ intruptible (), e down () e down_ intruptible () para semáforos). As versões interruptíveis permitem que a tarefa seja interrompida por um sinal, e então acordar para processá-lo antes que o bloqueio é adquirido. O tempo em lock sleeps ininterrupta geralmente não adiciona muito às médias de carga, mas neste caso eles estão adicionando 0,30., Se isto fosse muito maior, valeria a pena analisar para ver se a contenção de bloqueio poderia ser reduzida (eg, eu começaria a cavar no systemd-journal e no proc_pid_cmdline_read()!), o que deverá melhorar o desempenho e reduzir a média de carga.faz sentido que estes caminhos de código sejam incluídos na média de carga? Sim, diria que sim. Esses fios estão no meio do trabalho, e por acaso bloqueiam uma fechadura. Não estão inactivos. Eles são demanda no sistema, embora para recursos de software em vez de recursos de hardware.,
Decomposing Linux load averages
Can the Linux load average value be fully decomposed into components? Aqui está um exemplo: em um sistema de 8 CPU ocioso, eu lancei tar para arquivar alguns arquivos não-acoplados. Ele passa vários minutos na maioria bloqueados em leitura de disco. Aqui estão as estatísticas, coletadas de três janelas terminais diferentes:
I também coletou um grafo de chama Off-CPU apenas para o estado ininterrupto (SVG):

a média de carga de um minuto final é de 1,19. Deixe-me decompor que:
- 0, 33 é do tempo de CPU do tar (pidstat)
- 0.,67 é de alcatrão do ininterrupta leituras de disco, inferido (offcpu chama gráfico tem isso no 0.69, eu suspeito que como ele começou a colecionar um pouco mais tarde e se estende um pouco diferente do tempo de intervalo)
- 0.04 é de CPU consumidores (iostat usuário + sistema, menos alcatrão da CPU a partir de pidstat)
- 0.11 é de kernel trabalhadores ininterrupta e/S de disco do tempo, de lavagem, de gravações de disco (offcpu chama gráfico, as duas torres na esquerda)
Que adiciona até 1.15. Ainda me falta o 0.,04, alguns dos quais podem ser arredondamentos e intervalos de medição Erros de deslocamento, mas um lote pode ser devido à média de carga ser uma soma em movimento exponencialmente-dampado, enquanto as outras médias que eu estou usando (pidstat, iostat) são médias normais. Antes de 1,19, a média de um minuto era 1,25, por isso, parte disso ainda vai arrastar-nos alto. Quanto? A partir de meus gráficos anteriores, na marca de um minuto, 62% da métrica era daquele minuto, e o resto era mais velho. Então 0,62 x 1,15 + 0,38 x 1,25 = 1,18. Isso é muito perto do 1.19 relatado.,
Este é um sistema onde um thread (tar) mais um pouco mais (algum tempo em threads do kernel worker) estão fazendo trabalho, e Linux relata a média de carga como 1.19, o que faz sentido. Se ele estava medindo “médias de carga de CPU”, o sistema teria relatado 0,37 (inferido do resumo de mpstat), o que é correto apenas para recursos de CPU, mas esconde o fato de que há demanda por mais de um fio de trabalho.
espero que este exemplo mostre que os números realmente significam algo deliberado (CPU + ininterrupto), e você pode decompô-los e descobri-lo.,
fazendo sentido das médias de carga do Linux
eu cresci com Osses onde as médias de carga significavam médias de carga do CPU, então a versão Linux sempre me incomodou. Talvez o verdadeiro problema seja que as palavras ” médias de carga “são tão ambíguas quanto”I/O”. Que tipo de E/S? Disk I / O? Sistema de ficheiros? Rede De E / S? … Da mesma forma, quais as médias de carga? Médias de carga do CPU? Médias de carga do sistema?, Clarificá-lo desta forma permite-me fazer sentido dele assim:
- no Linux, as médias de carga são (ou tentar ser) “médias de carga do sistema”, para o sistema como um todo, medindo o número de threads que estão funcionando e esperando para funcionar (CPU, disco, bloqueios ininterruptos). Dito de forma diferente, ele mede o número de fios que não são completamente ociosos. Vantagem: inclui a demanda por diferentes recursos.
- em outros SOs, as médias de carga são “médias de carga de CPU”, medindo o número de tarefas executáveis de CPU + tarefas executáveis de CPU. Vantagem: pode ser mais fácil de entender e raciocinar sobre (apenas para CPUs).,
Note que há outro tipo possível:” médias de carga de recursos físicos”, que incluiria carga apenas para recursos físicos (CPU + disco).
talvez um dia vamos adicionar médias de carga adicionais ao Linux, e deixar o usuário escolher o que eles querem usar: uma “média de carga de CPU” separada, “médias de carga de disco”, “médias de carga de rede”, etc. Ou usar métricas diferentes.o que é uma média de carga” boa “ou” má”?,
Algumas pessoas têm encontrado valores que parecem funcionar para os seus sistemas e cargas de trabalho: eles sabem que, quando a carga passa sobre X, aplicação de latência é alta e os clientes começam a reclamar. Mas não há regras para isto.
com médias de carga de CPU, pode-se dividir o valor pela contagem de CPU, então dizer que se essa razão é superior a 1,0 você está correndo na saturação, o que pode causar problemas de desempenho., É um pouco ambíguo, pois é uma média de longo prazo (pelo menos um minuto) que pode esconder a variação. Um sistema com uma proporção de 1,5 pode estar funcionando bem, enquanto outro com 1,5 que foi bursty dentro do minuto pode estar funcionando mal.
I uma vez administrou um servidor de E-mail de duas CPU que durante o dia correu com uma média de carga de CPU entre 11 e 16 (um rácio entre 5.5 e 8). A latência era aceitável e ninguém se queixava. Este é um exemplo extremo: a maioria dos sistemas vai sofrer com uma relação carga/CPU de apenas 2.,
as for Linux’s system load averages: these are even more ambuble as they cover different resource types, so you can’t just divide by the CPU count. É mais útil para comparações relativas: se você sabe que o sistema funciona bem em uma carga de 20, e está agora em 40, então é hora de cavar com outras métricas para ver o que está acontecendo.
melhores métricas
quando as médias de carga do Linux aumentam, você sabe que tem maior demanda por recursos (CPUs, discos e alguns bloqueios), mas você não tem certeza de qual. Você pode usar outras métricas para clarificação., Por exemplo, para CPUs:
os dois primeiros são métricas de Utilização, os três últimos são métricas de saturação. Métricas de Utilização são úteis para a caracterização de carga de trabalho, e métricas de saturação úteis para identificar um problema de desempenho. As melhores métricas de saturação do CPU são medidas de latência na fila de execução( ou scheduler): a hora em que uma tarefa/thread estava em um estado executável, mas teve que esperar sua vez. Estes permitem que você calcule a magnitude de um problema de desempenho, por exemplo, a percentagem de tempo gasto em latência scheduler., Medir o comprimento da fila de execução pode sugerir que há um problema, mas é mais difícil estimar a magnitude.
a facilidade schedstats foi feita uma sintonização do kernel no Linux 4.6 (kernel sysctl.sched_ schedstats) e alterado para estar desligado por omissão. A Contabilidade de atraso expõe a mesma métrica de latência scheduler, que está no cpustat e eu sugeri apenas adicioná-la ao htop também, pois isso tornaria mais fácil para as pessoas usarem., Mais fácil do que, por exemplo, raspar a métrica de tempo de espera (latência scheduler) da (não documentada) /proc/sched_ Dug:
para além das métricas de CPU, Você também pode procurar por métricas de utilização e saturação para dispositivos de disco. Eu me concentro em tais métricas no método de uso, e tenho uma lista de verificação Linux desses.
embora existam métricas mais explícitas, isso não significa que as médias de carga são inúteis. Eles são usados com sucesso em políticas de escala-up para micro-serviços de computação em nuvem, juntamente com outras métricas. Isto ajuda os micro-serviços a responder a diferentes tipos de aumento de carga, CPU ou disco I / O., Com estas políticas é mais seguro errar em escala acima (custando dinheiro) do que não escalar acima (custando clientes), assim que incluir mais Sinais é desejável. Se aumentarmos demasiado, vamos descobrir porquê no dia seguinte.
a única coisa pela qual continuo a usar médias de carga é a sua informação histórica. Se me pedirem para verificar uma instância de mau desempenho na nuvem, em seguida, entrar e descobrir que a média de um minuto é muito menor do que a média de quinze minutos, é uma grande pista de que eu poderia ser tarde demais para ver a questão de desempenho ao vivo., Mas eu só passo alguns segundos contemplando médias de carga, antes de voltar para outras métricas.
Conclusion
In 1993, a Linux engineer found a nonintuitive case with load averages, and with a three-line patch changed them forever from ” CPU load averages “to what one might call” system load averages. Sua mudança incluiu tarefas no estado ininterrupto, de modo que as médias de carga refletiam a demanda por recursos de disco e não apenas CPUs., Estas médias de carga do sistema contam o número de threads trabalhando e esperando para trabalhar, e são resumidas como um tripleto de médias móveis exponencialmente amortecidas que usam 1, 5 e 15 minutos como constantes em uma equação. Este tripleto de Números permite-lhe ver se a carga está a aumentar ou a diminuir, e o seu maior valor pode ser para comparações relativas consigo próprios.
o uso do estado ininterrupto tem crescido desde então no kernel Linux, e hoje inclui primitivas de bloqueio ininterruptas., Se a média de carga é uma medida da demanda em termos de execução e espera threads (e não estritamente threads querendo recursos de hardware), então eles ainda estão trabalhando da maneira que queremos que eles.
neste post, eu desenterrei o patch médio de carga Linux a partir de 1993 – o que foi surpreendentemente difícil de encontrar-contendo a explicação original pelo autor. Também medi traços de pilha e tempo no estado ininterrupto usando bcc/eBPF em um sistema Linux moderno, e visualizei desta vez como um grafo de chama off-CPU., Esta visualização fornece muitos exemplos de dormidas ininterruptas, e pode ser gerada sempre que necessário para explicar médias de carga invulgarmente altas. Eu também propus outras métricas que você pode usar para entender a carga do sistema em mais detalhes, em vez de médias de carga.
terminarei citando um comentário no topo do kernel/sched/loadavg.c na fonte Linux, pelo mantenedor do scheduler Peter Zijlstra:
* este arquivo contém os bits mágicos necessários para computar o loadavg global
* figura. É um número tolo, mas as pessoas acham que é importante., We go through
* great pains to make it work on big machines and tickless kernels.
- Saltzer, J., and J. Gintell. “The Instrumentation of Multics,” CACM, August 1970 (explains exponentials).
- Multics system_performance_graph command reference (menciona a média de 1 minuto).
- TENEX código fonte (o código médio de carga está em SCHED.ISENCAO).
- RFC 546 “TENEX Load Averages for July 1973” (explains measuring CPU demand).Bobrow, D., et al., “TENEX: a Paged Time Sharing System for the PDP-10,” Communications of the ACM, March 1972 (explains the load average triplet).
- Gunther, N. “UNIX Load Average Part 1: How It Works” PDF (explica os cálculos exponenciais).
- O email de Linus sobre o Linux 0.99 patchlevel 14.
- a mudança média de carga e-mail Está ligado oldlinux.org (in alan-old-funet-lists / kernel.1993.gz, e não nos diretórios linux, que eu procurei primeiro).
- o kernel Linux / sched.C Fonte antes e depois da variação média da carga: 0,99.13, 0,99.14.Tarballs Para Linux 0.,99 lançamentos estão em kernel.org.
- o actual Código médio de carga do Linux: loadavg.c, loadavg.h
- as ferramentas de análise bcc incluem o meu offcputime, usado para rastrear o TASK_ uninterruptible.os gráficos de chama foram usados para visualizar caminhos ininterruptos.graças a Deirdre Straughan pelas Edições.