Introducere
Random forest este un supravegheate algoritm de învățare care este folosit atât pentru clasificarea precum și de regresie. Dar, totuși, este folosit în principal pentru probleme de clasificare. După cum știm că o pădure este alcătuită din copaci și mai mulți copaci înseamnă pădure mai robustă., În mod similar, algoritmul forestier aleatoriu creează arbori de decizie pe eșantioane de date și apoi primește Predicția de la fiecare dintre ele și, în final, selectează cea mai bună soluție prin vot. Este o metodă de ansamblu care este mai bună decât un singur arbore de decizie, deoarece reduce supra-montarea prin medierea rezultatului.
lucrul algoritmului forestier aleatoriu
putem înțelege lucrul algoritmului forestier aleatoriu cu ajutorul următorilor pași −
-
Pasul 1 − în primul rând, începeți cu selectarea probelor aleatorii dintr-un anumit set de date.,pasul 2-în continuare, acest algoritm va construi un arbore de decizie pentru fiecare eșantion. Apoi va obține rezultatul predicției din fiecare arbore de decizie.Pasul 3-în această etapă, votarea va fi efectuată pentru fiecare rezultat prezis.pasul 4-în cele din urmă, selectați cel mai votat rezultat de predicție ca rezultat final de predicție.,
diagrama De mai jos va ilustra sale de lucru −
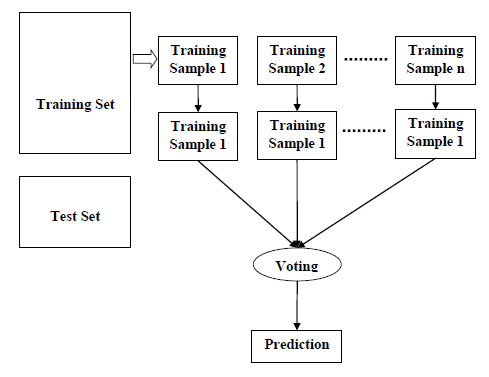
punerea în Aplicare în Python
în Primul rând, începe cu importul necesar pachetele Python −
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd
Apoi, descărcați setul de date iris din weblink, după cum urmează −
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
apoi, avem nevoie pentru a atribui nume de coloană pentru setul de date după cum urmează −
headernames =
Acum, avem nevoie pentru a citi date la panda dataframe după cum urmează −
dataset = pd.read_csv(path, names = headernames)dataset.head()
Preprocesarea Datelor se va face cu ajutorul următorul script linii.,
X = dataset.iloc.valuesy = dataset.iloc.values
în continuare, vom împărți datele în împărțirea trenului și a testului. Codul de mai jos va împărți setul de date în 70% de date de instruire și 30% de date de testare −
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30)
Apoi, trenul modelul cu ajutorul RandomForestClassifier clasa de sklearn după cum urmează −
În sfârșit, avem nevoie pentru a face predicția., Se poate face cu ajutorul următorul script −
y_pred = classifier.predict(X_test)
Apoi, imprima rezultatele după cum urmează −
Ieșire
Pro și Contra de Pădure Aleatoriu
Pro
următoarele sunt avantajele de Pădure Aleatoare algoritm −
-
Acesta depaseste problema de overfitting de medie sau de combinare a rezultatelor din diferite arbori de decizie.
-
pădurile aleatorii funcționează bine pentru o gamă largă de elemente de date decât un singur arbore de decizie.
-
Pădurea aleatorie are o variație mai mică decât arborele de decizie unic.,
-
pădurile aleatorii sunt foarte flexibile și posedă o precizie foarte mare.scalarea datelor nu este necesară în algoritmul forestier aleatoriu. Menține o precizie bună chiar și după furnizarea de date fără scalare.
-
algoritmi de pădure aleatoare menține o precizie bună chiar și o mare parte din datele lipsesc.
contra
următoarele sunt dezavantajele algoritmului forestier aleatoriu −
-
complexitatea este principalul dezavantaj al algoritmilor Forestieri aleatorii.,construcția pădurilor aleatorii este mult mai dificilă și consumă mult timp decât copacii de decizie.mai multe resurse de calcul sunt necesare pentru a implementa algoritmul forestier aleatoriu.este mai puțin intuitiv în cazul în care avem o colecție mare de arbori de decizie.procesul de predicție folosind păduri aleatorii consumă foarte mult timp în comparație cu alți algoritmi.