Introducción
Random forest es un algoritmo de aprendizaje supervisado que se utilizan para la clasificación de regresión. Sin embargo, se utiliza principalmente para problemas de clasificación. Como sabemos, un bosque se compone de árboles y más árboles significa un bosque más robusto., Del mismo modo, Random forest algorithm crea árboles de decisión en muestras de datos y luego obtiene la predicción de cada uno de ellos y finalmente selecciona la mejor solución por medio de la votación. Es un método de conjunto que es mejor que un solo árbol de decisión porque reduce el ajuste excesivo al promediar el resultado.
trabajo del algoritmo de bosque Aleatorio
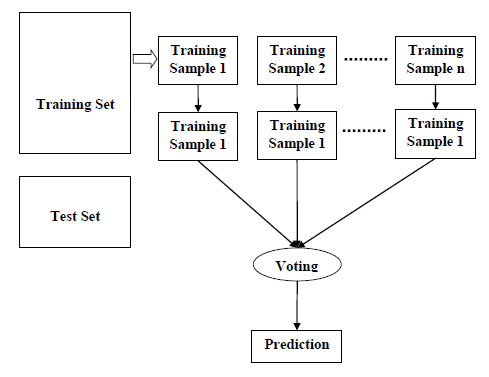
podemos entender el trabajo del algoritmo de bosque Aleatorio con la ayuda de los siguientes pasos −
-
Paso 1 − primero, comience con la selección de muestras aleatorias de un conjunto de datos dado.,
-
Paso 2-a continuación, este algoritmo construirá un árbol de decisiones para cada muestra. Entonces obtendrá el resultado de la predicción de cada árbol de decisión.
-
Paso 3-en este paso, la votación se realizará para cada resultado previsto.
-
Paso 4-por último, seleccione el resultado de predicción más votado como el resultado de predicción final.,
el siguiente diagrama ilustrará su funcionamiento −
implementación en Python
primero, comience con la importación de paquetes Python necesarios −
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd
a continuación, descargue el conjunto de datos iris desde su enlace web de la siguiente manera −
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
a continuación, necesitamos asignar nombres de columna al conjunto de datos de la siguiente manera −
headernames =
ahora, necesitamos leer el conjunto de datos en pandas dataframe de la siguiente manera −
dataset = pd.read_csv(path, names = headernames)dataset.head()
el preprocesamiento de datos se realizará con la ayuda del siguiente script líneas.,
X = dataset.iloc.valuesy = dataset.iloc.values
a continuación, dividiremos los datos en tren y división de prueba. El siguiente código dividirá el conjunto de datos en 70% de datos de entrenamiento y 30% de datos de prueba −
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30)
a continuación, entrena el modelo con la ayuda de la clase RandomForestClassifier de sklearn de la siguiente manera −
Por fin, necesitamos hacer la predicción., Se puede hacer con la ayuda del siguiente script −
y_pred = classifier.predict(X_test)
a continuación, imprima los resultados de la siguiente manera −
salida
Pros y contras de Random Forest
Pros
las siguientes son las ventajas del algoritmo Random Forest −
-
supera el problema de sobreajustar promediando o combinando los resultados de diferentes árboles de decisión.
-
Los bosques aleatorios funcionan bien para una amplia gama de elementos de datos que un solo árbol de decisiones.
-
El Bosque Aleatorio tiene menos varianza que el árbol de decisión único.,
-
bosques Aleatorios son muy flexibles y poseen una precisión muy alta.
-
el escalado de datos no requiere en el algoritmo de bosque Aleatorio. Mantiene una buena precisión incluso después de proporcionar datos sin escalado.
-
Los algoritmos de Bosques aleatorios mantienen una buena precisión incluso si falta una gran proporción de los datos.
Cons
las siguientes son las desventajas del algoritmo de bosque Aleatorio –
-
la complejidad es la principal desventaja de los Algoritmos de bosque Aleatorio.,
-
la construcción de bosques aleatorios es mucho más difícil y requiere mucho tiempo que los árboles de decisión.
-
Se requieren más recursos computacionales para implementar el algoritmo de bosque Aleatorio.
-
es menos intuitivo en caso de que tengamos una gran colección de árboles de decisión.
-
el proceso de predicción utilizando bosques aleatorios consume mucho tiempo en comparación con otros algoritmos.